User login
Evaluating GPT-4o for Automated Classification of Skin Lesions Using the HAM10000 Dataset
To the Editor:
The widespread availability and popularity of ChatGPT (OpenAI) have sparked interest in its potential applications within various fields, including medical diagnostics.1 In dermatology, large language models (LLMs) already are being cited as a possible way to reliably respond to common patient queries and produce concise patient education materials.2,3 That being said, there is skepticism regarding the technology’s efficacy and reliability in producing accurate treatment plans, with variability among popular LLMs; for example, a recent study by Chau et al4 demonstrated that ChatGPT was best at providing specific and accurate information regarding patient-facing responses to questions about 5 dermatologic diagnoses compared to Google Bard (now rebranded as Google Gemini) and Bing AI (now rebranded as Microsoft Copilot), which more often produced inaccurate or nonspecific responses. Google Bard also declined to answer one prompt.4 Large language models also have been evaluated in diagnosing skin lesions. In 2024, SkinGPT-4 (a pretrained multimodel LLM developed by Zhou et al5) achieved just over 80% accuracy in interpreting images of skin lesions and was considered informative by 82.5% of board-certified dermatologists, demonstrating that LLMs may have the potential to become integrated into clinical practice.5
Our study aimed to evaluate the performance of GPT-4o (OpenAI)—a widely accessible, low-cost LLM—in diagnosing dermatologic conditions using the HAM10000 dataset, a well-curated collection of dermatoscopic images developed for training and benchmarking artificial intelligence (AI) algorithms.6 HAM10000 comprises images representing 7 distinct skin conditions: actinic keratoses (ak), basal cell carcinoma (bcc), benign keratosis (bk), dermatofibroma (df), melanoma (mel), melanocytic nevi (nv), and vascular skin lesions (vsl), providing a robust platform for multiclass classification assessment. We evaluated GPT-4o using 100 dermatoscopic images per condition to assess diagnostic accuracy, potential biases, and limitations in skin lesion identification. The HAM10000 dataset was selected because it offers a large standardized reference set of dermatoscopic (rather than conventional clinical) images commonly used in dermatologic AI research. GPT-4o was chosen due to its patient-friendly interface, widespread use, and prior reports suggesting greater reliability in skin lesion assessment compared with other LLMs.
One hundred images from each of the 7 dermatologic categories were randomly selected for use in our analysis in 2024. The images were selected by our data scientist (J.C.) through random sampling from the dataset. Each image was separately presented to GPT-4o without any preprocessing or modification alongside 2 prompts designed to evaluate the diagnostic capabilities of GPT-4o. Both prompts included the same list of 7 dermatologic conditions for answer choices but differed in contextual information, where prompt 1 provided patient demographic information and localization of the dermatological condition but prompt 2 did not provide these details (Table). No follow-up questions were presented.

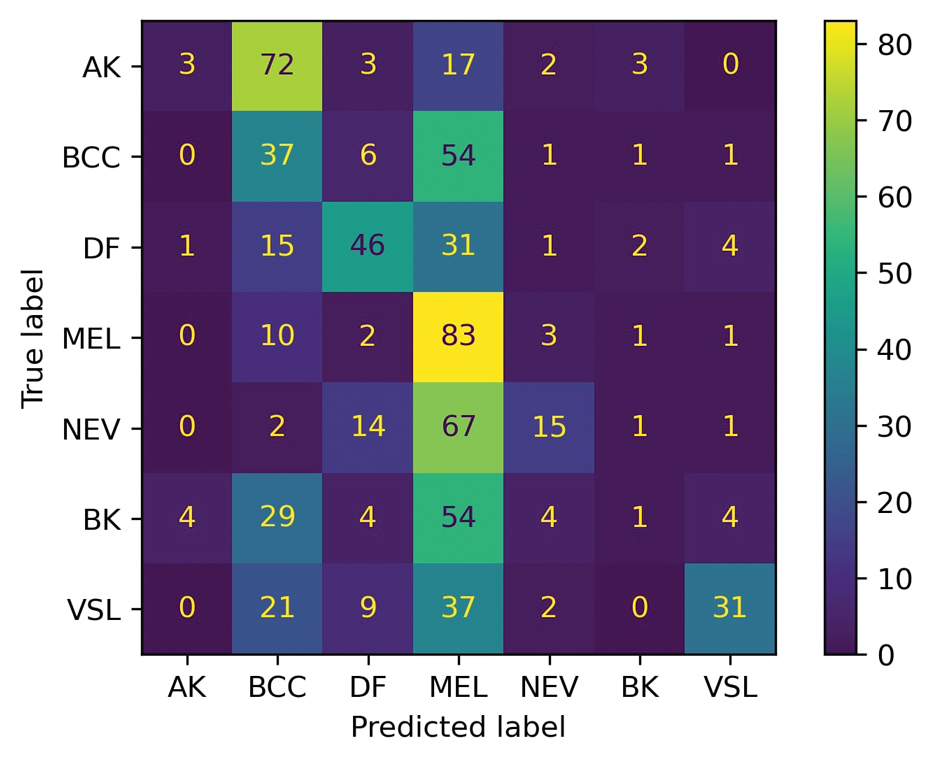
For prompt 1, the confusion matrix showed a strong bias toward detecting mel and bcc, with high true positives (mel, 83%; bcc, 37%)(eFigure 1). This pattern possibly suggests a tendency to favor malignant labels (eg, mel, BCC) when uncertainty is present. Interestingly, df and vsl also had notable true positives (46% and 37%, respectively), which is unexpected for less critical conditions because the model’s correct classifications were uneven across benign lesions. Actinic keratoses and nv showed higher misclassification rates, suggesting the model struggled to distinguish them from other lesions.
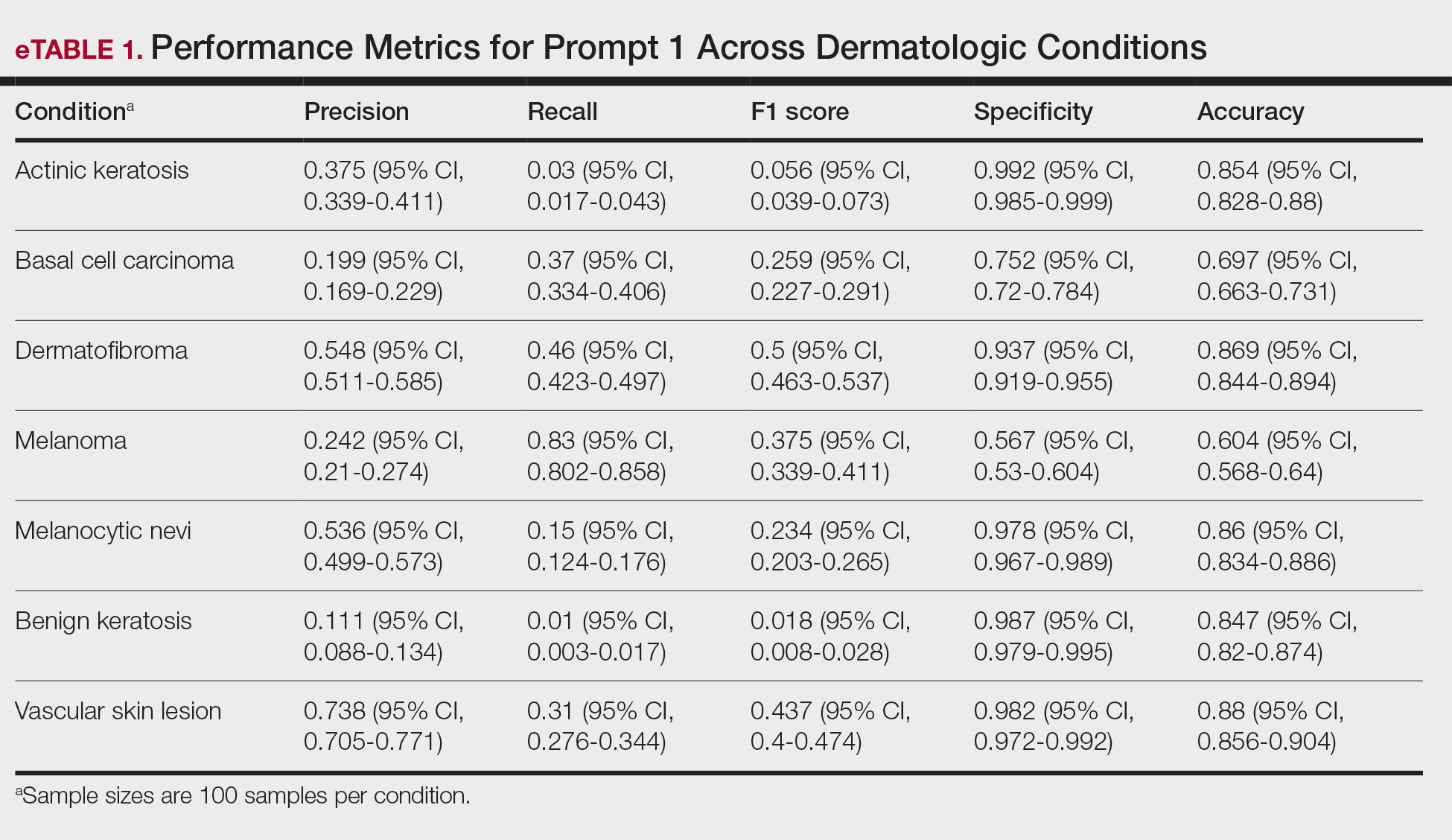
As shown in eTable 1, prompt 1 exhibited the highest recall for mel at 0.83 but performed worse in precision (0.242) and specificity (0.567) compared to ak, which had an extremely low recall (0.03) but very high specificity (0.992) and moderate precision score (0.375). The highest precision score was seen with vsl (0.738), which also achieved high scores in specificity (0.982) and accuracy (0.88) and performed moderately well in recall (0.31). All performance metrics are reported as proportions (0-1.0), wherein 1.0 indicates 100.
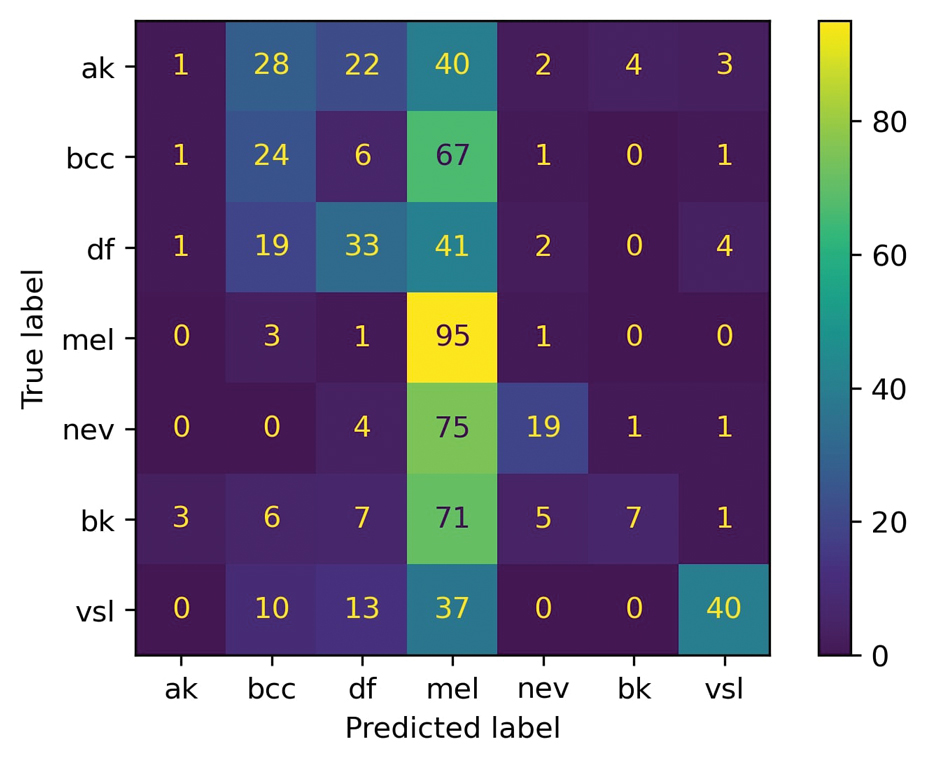
For prompt 2, the second confusion matrix followed similar trends as prompt 1 but still differed in key areas (eFigure 2). Melanoma detection remained strong (true positives, 95%), while bcc shows slightly fewer true positives (24%). Vascular skin lesions improve in true positives (40%), and df dropped slightly (33%). The model continues to struggle with ak and nv, with notable misclassifications observed across other categories
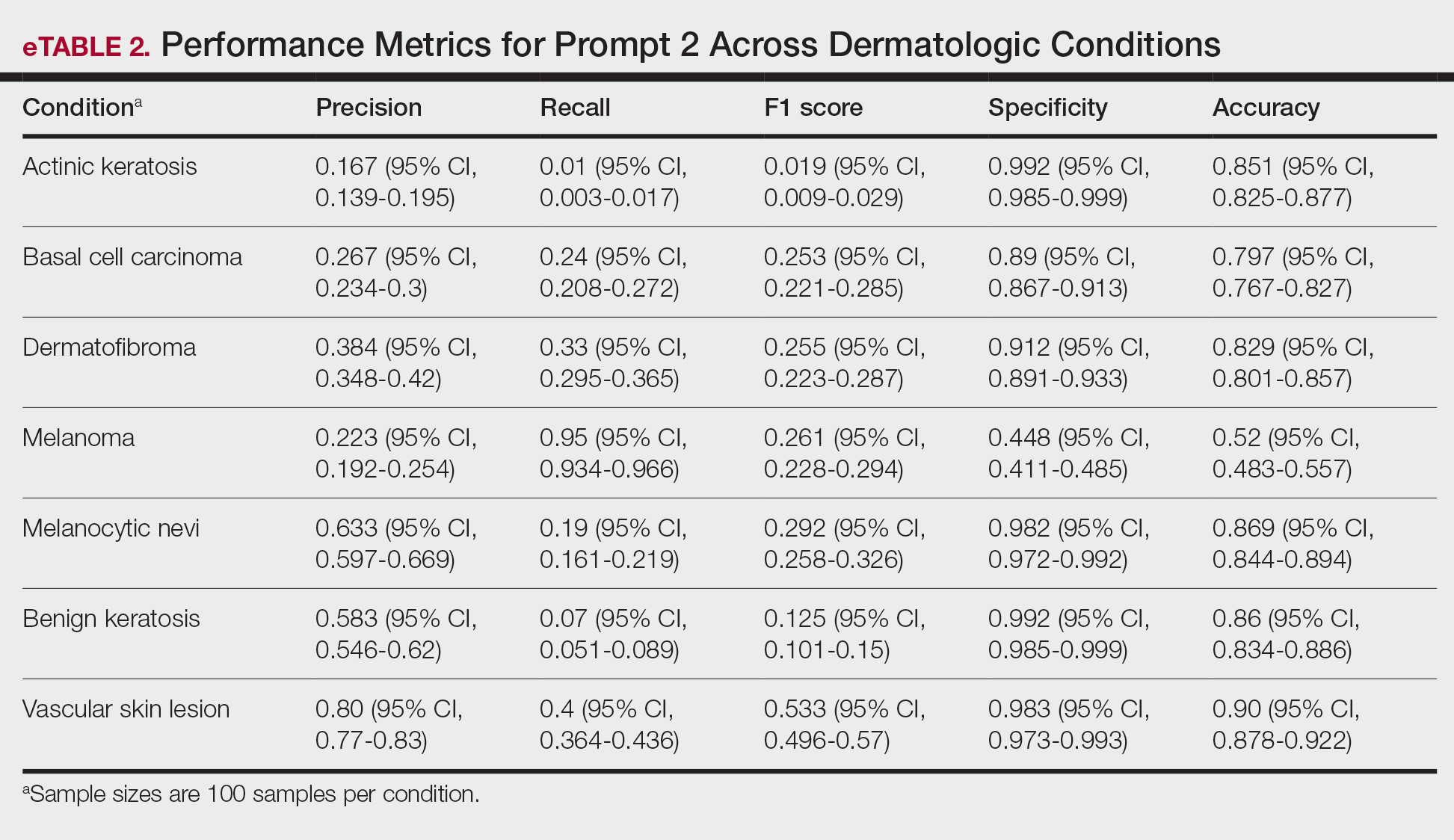
Similar to prompt 1, prompt 2 achieved its highest recall for mel (0.95%), but demonstrated lower precision (0.223%) and specificity (0.488%) for this class. Prompt 2 also produced the highest accuracy for vascular skin lesions (0.90%). The highest specificity was observed for both bk and ak (0.992% each); however, ak again demonstrated the lowest recall, with a value of 0.01%.
A previous study utilizing a model of binary classification to distinguish between mel and benign dermatologic conditions demonstrated poor performance.1 Additionally, prior studies have employed a less-strict, open-ended style question approach to examine ChatGPT’s ability to diagnose mel with limited efficacy.7 The HAM10000 dataset was specifically selected despite its limitations (including the absence of clinical images and limited diversity in skin tones) due to its comprehensive nature, robust annotation standards, and widespread acceptance in dermatologic AI research. Compared to the Diverse Dermatology Images dataset, which notably lacks skin tone diversity, HAM10000 provides a balanced representation of several dermatologic conditions crucial for multiclass classification tasks, making it suitable for benchmarking AI performance. This study aimed to eliminate these limitations by employing a multiclass classification approach; however, despite this switch, our results indicate continued and major limitations of the diagnostic capabilities of GPT-4o.
In its current form, GPT-4o appeared to demonstrate a clear accuracy bias toward correctly identifying specific and severe dermatologic conditions (eg, mel, bcc) but showed low and variable class-level performance for other categories (eg, ak, nv, df, vsl), with frequent misclassification into melanoma or basal cell carcinoma and low recall for some classes (eTables 1 and 2). This finding emphasized that GPT-4o currently lacks the reliability needed for real-life clinical applications in dermatology, as both binary and multiclass models fail to achieve consistent accurate performance across all skin conditions. Notably, GPT-4o may generate false-positive malignant classifications among patients due to its skew in predicted labels toward labeling benign lesions as malignant.
From the patient perspective, younger individuals may upload images of benign nevi only to unnecessarily fear a mel diagnosis after receiving GPT-4o results. Statistically, younger patients are less likely than older patients to have malignant lesions and more likely to instead present with common vsl or df—lesions that GPT-4o appears likely to identify correctly.8 For older users, however, the situation may differ. Beyond ak being misclassified as bcc, older patients also may encounter GPT-4o outputs that mislabel lesions as mel, raising concerns and heightening anxiety. Given the technology’s tendency to overestimate the risk of serious dermatologic conditions, this behavior poses a considerable challenge in its current state and may inadvertently intensify public anxiety around mel.
A notable limitation of our study was that, compared to publicly available datasets, the HAM10000 dataset includes only dermatoscopic images rather than a combination of clinical and dermatoscopic images. Furthermore, the HAM10000 dataset comprises images primarily from White patients, whereas other diverse databases (eg, the Diverse Dermatology Images dataset) may be more suitable for training AI algorithms to accurately diagnose skin lesions in individuals with a variety of skin tones.9
Ultimately, our results signal that major advancements in the design and training of LLMs such as GPT-4o are necessary before these systems can be integrated into dermatologic diagnostic decision-making to offer benefit rather than cause harm. Consulting a health care professional rather than relying solely on AI, which might otherwise lead to avoidable stress, unnecessary alarm, and potentially increased health care costs due to unwarranted follow-up and testing, should remain the recommended standard of care for patients suspecting a skin lesion.
- Caruccio L, Cirillo S, Polese G, et al. Can ChatGPT provide intelligent diagnoses? A comparative study between predictive models and ChatGPT to define a new medical diagnostic bot. Expert Syst Appl. 2024;235:121186. doi:10.1016/j.eswa.2023.121186
- Ferreira AL, Chu B, Grant-Kels JM, et al. Evaluation of ChatGPT dermatology responses to common patient queries. JMIR Dermatol. 2023;6:E49280. doi:10.2196/49280
- Chen R, Zhang Y, Choi S, et al. The chatbots are coming: risks and benefits of consumer-facing artificial intelligence in clinical dermatology. J Am Acad Dermatol. 2023;89:872-874. doi:10.1016/j.jaad.2023.05.088
- Chau C, Feng H, Cobos G, et al. The comparative sufficiency of ChatGPT, Google Bard, and Bing AI in answering diagnosis, treatment, and prognosis questions about common dermatological diagnoses. JMIR Dermatol. 2025;8:E60827. doi:10.2196/60827
- Zhou J, He X, Sun L, et al. Pre-trained multimodal large language model enhances dermatological diagnosis using SkinGPT-4. Nat Commun. 2024;15:5649. doi:10.1038/s41467-024-50043-3
- Tschandl P, Rosendahl C, Kittler H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci Data. 2018;5:180161. doi:10.1038/sdata.2018.161
- Shifai N, van Doorn R, Malvehy J, et al. Can ChatGPT vision diagnose melanoma? An exploratory diagnostic accuracy study. J Am Acad Dermatol. 2024;90:1057-1059. doi:10.1016/j.jaad.2023.12.062
- Cortez JL, Vasquez J, Wei ML. The impact of demographics, socioeconomics, and health care access on melanoma outcomes. J Am Acad Dermatol. 2021;84:1677-1683. doi:10.1016/j.jaad.2020.07.125
- Daneshjou R, Vodrahalli K, Novoa RA, et al. Disparities in dermatology AI performance on a diverse, curated clinical image set. Sci Adv. 2022;8:Eabq6147. doi:10.1126/sciadv.abq6147
To the Editor:
The widespread availability and popularity of ChatGPT (OpenAI) have sparked interest in its potential applications within various fields, including medical diagnostics.1 In dermatology, large language models (LLMs) already are being cited as a possible way to reliably respond to common patient queries and produce concise patient education materials.2,3 That being said, there is skepticism regarding the technology’s efficacy and reliability in producing accurate treatment plans, with variability among popular LLMs; for example, a recent study by Chau et al4 demonstrated that ChatGPT was best at providing specific and accurate information regarding patient-facing responses to questions about 5 dermatologic diagnoses compared to Google Bard (now rebranded as Google Gemini) and Bing AI (now rebranded as Microsoft Copilot), which more often produced inaccurate or nonspecific responses. Google Bard also declined to answer one prompt.4 Large language models also have been evaluated in diagnosing skin lesions. In 2024, SkinGPT-4 (a pretrained multimodel LLM developed by Zhou et al5) achieved just over 80% accuracy in interpreting images of skin lesions and was considered informative by 82.5% of board-certified dermatologists, demonstrating that LLMs may have the potential to become integrated into clinical practice.5
Our study aimed to evaluate the performance of GPT-4o (OpenAI)—a widely accessible, low-cost LLM—in diagnosing dermatologic conditions using the HAM10000 dataset, a well-curated collection of dermatoscopic images developed for training and benchmarking artificial intelligence (AI) algorithms.6 HAM10000 comprises images representing 7 distinct skin conditions: actinic keratoses (ak), basal cell carcinoma (bcc), benign keratosis (bk), dermatofibroma (df), melanoma (mel), melanocytic nevi (nv), and vascular skin lesions (vsl), providing a robust platform for multiclass classification assessment. We evaluated GPT-4o using 100 dermatoscopic images per condition to assess diagnostic accuracy, potential biases, and limitations in skin lesion identification. The HAM10000 dataset was selected because it offers a large standardized reference set of dermatoscopic (rather than conventional clinical) images commonly used in dermatologic AI research. GPT-4o was chosen due to its patient-friendly interface, widespread use, and prior reports suggesting greater reliability in skin lesion assessment compared with other LLMs.
One hundred images from each of the 7 dermatologic categories were randomly selected for use in our analysis in 2024. The images were selected by our data scientist (J.C.) through random sampling from the dataset. Each image was separately presented to GPT-4o without any preprocessing or modification alongside 2 prompts designed to evaluate the diagnostic capabilities of GPT-4o. Both prompts included the same list of 7 dermatologic conditions for answer choices but differed in contextual information, where prompt 1 provided patient demographic information and localization of the dermatological condition but prompt 2 did not provide these details (Table). No follow-up questions were presented.
For prompt 1, the confusion matrix showed a strong bias toward detecting mel and bcc, with high true positives (mel, 83%; bcc, 37%)(eFigure 1). This pattern possibly suggests a tendency to favor malignant labels (eg, mel, BCC) when uncertainty is present. Interestingly, df and vsl also had notable true positives (46% and 37%, respectively), which is unexpected for less critical conditions because the model’s correct classifications were uneven across benign lesions. Actinic keratoses and nv showed higher misclassification rates, suggesting the model struggled to distinguish them from other lesions.
As shown in eTable 1, prompt 1 exhibited the highest recall for mel at 0.83 but performed worse in precision (0.242) and specificity (0.567) compared to ak, which had an extremely low recall (0.03) but very high specificity (0.992) and moderate precision score (0.375). The highest precision score was seen with vsl (0.738), which also achieved high scores in specificity (0.982) and accuracy (0.88) and performed moderately well in recall (0.31). All performance metrics are reported as proportions (0-1.0), wherein 1.0 indicates 100.
For prompt 2, the second confusion matrix followed similar trends as prompt 1 but still differed in key areas (eFigure 2). Melanoma detection remained strong (true positives, 95%), while bcc shows slightly fewer true positives (24%). Vascular skin lesions improve in true positives (40%), and df dropped slightly (33%). The model continues to struggle with ak and nv, with notable misclassifications observed across other categories
Similar to prompt 1, prompt 2 achieved its highest recall for mel (0.95%), but demonstrated lower precision (0.223%) and specificity (0.488%) for this class. Prompt 2 also produced the highest accuracy for vascular skin lesions (0.90%). The highest specificity was observed for both bk and ak (0.992% each); however, ak again demonstrated the lowest recall, with a value of 0.01%.
A previous study utilizing a model of binary classification to distinguish between mel and benign dermatologic conditions demonstrated poor performance.1 Additionally, prior studies have employed a less-strict, open-ended style question approach to examine ChatGPT’s ability to diagnose mel with limited efficacy.7 The HAM10000 dataset was specifically selected despite its limitations (including the absence of clinical images and limited diversity in skin tones) due to its comprehensive nature, robust annotation standards, and widespread acceptance in dermatologic AI research. Compared to the Diverse Dermatology Images dataset, which notably lacks skin tone diversity, HAM10000 provides a balanced representation of several dermatologic conditions crucial for multiclass classification tasks, making it suitable for benchmarking AI performance. This study aimed to eliminate these limitations by employing a multiclass classification approach; however, despite this switch, our results indicate continued and major limitations of the diagnostic capabilities of GPT-4o.
In its current form, GPT-4o appeared to demonstrate a clear accuracy bias toward correctly identifying specific and severe dermatologic conditions (eg, mel, bcc) but showed low and variable class-level performance for other categories (eg, ak, nv, df, vsl), with frequent misclassification into melanoma or basal cell carcinoma and low recall for some classes (eTables 1 and 2). This finding emphasized that GPT-4o currently lacks the reliability needed for real-life clinical applications in dermatology, as both binary and multiclass models fail to achieve consistent accurate performance across all skin conditions. Notably, GPT-4o may generate false-positive malignant classifications among patients due to its skew in predicted labels toward labeling benign lesions as malignant.
From the patient perspective, younger individuals may upload images of benign nevi only to unnecessarily fear a mel diagnosis after receiving GPT-4o results. Statistically, younger patients are less likely than older patients to have malignant lesions and more likely to instead present with common vsl or df—lesions that GPT-4o appears likely to identify correctly.8 For older users, however, the situation may differ. Beyond ak being misclassified as bcc, older patients also may encounter GPT-4o outputs that mislabel lesions as mel, raising concerns and heightening anxiety. Given the technology’s tendency to overestimate the risk of serious dermatologic conditions, this behavior poses a considerable challenge in its current state and may inadvertently intensify public anxiety around mel.
A notable limitation of our study was that, compared to publicly available datasets, the HAM10000 dataset includes only dermatoscopic images rather than a combination of clinical and dermatoscopic images. Furthermore, the HAM10000 dataset comprises images primarily from White patients, whereas other diverse databases (eg, the Diverse Dermatology Images dataset) may be more suitable for training AI algorithms to accurately diagnose skin lesions in individuals with a variety of skin tones.9
Ultimately, our results signal that major advancements in the design and training of LLMs such as GPT-4o are necessary before these systems can be integrated into dermatologic diagnostic decision-making to offer benefit rather than cause harm. Consulting a health care professional rather than relying solely on AI, which might otherwise lead to avoidable stress, unnecessary alarm, and potentially increased health care costs due to unwarranted follow-up and testing, should remain the recommended standard of care for patients suspecting a skin lesion.
To the Editor:
The widespread availability and popularity of ChatGPT (OpenAI) have sparked interest in its potential applications within various fields, including medical diagnostics.1 In dermatology, large language models (LLMs) already are being cited as a possible way to reliably respond to common patient queries and produce concise patient education materials.2,3 That being said, there is skepticism regarding the technology’s efficacy and reliability in producing accurate treatment plans, with variability among popular LLMs; for example, a recent study by Chau et al4 demonstrated that ChatGPT was best at providing specific and accurate information regarding patient-facing responses to questions about 5 dermatologic diagnoses compared to Google Bard (now rebranded as Google Gemini) and Bing AI (now rebranded as Microsoft Copilot), which more often produced inaccurate or nonspecific responses. Google Bard also declined to answer one prompt.4 Large language models also have been evaluated in diagnosing skin lesions. In 2024, SkinGPT-4 (a pretrained multimodel LLM developed by Zhou et al5) achieved just over 80% accuracy in interpreting images of skin lesions and was considered informative by 82.5% of board-certified dermatologists, demonstrating that LLMs may have the potential to become integrated into clinical practice.5
Our study aimed to evaluate the performance of GPT-4o (OpenAI)—a widely accessible, low-cost LLM—in diagnosing dermatologic conditions using the HAM10000 dataset, a well-curated collection of dermatoscopic images developed for training and benchmarking artificial intelligence (AI) algorithms.6 HAM10000 comprises images representing 7 distinct skin conditions: actinic keratoses (ak), basal cell carcinoma (bcc), benign keratosis (bk), dermatofibroma (df), melanoma (mel), melanocytic nevi (nv), and vascular skin lesions (vsl), providing a robust platform for multiclass classification assessment. We evaluated GPT-4o using 100 dermatoscopic images per condition to assess diagnostic accuracy, potential biases, and limitations in skin lesion identification. The HAM10000 dataset was selected because it offers a large standardized reference set of dermatoscopic (rather than conventional clinical) images commonly used in dermatologic AI research. GPT-4o was chosen due to its patient-friendly interface, widespread use, and prior reports suggesting greater reliability in skin lesion assessment compared with other LLMs.
One hundred images from each of the 7 dermatologic categories were randomly selected for use in our analysis in 2024. The images were selected by our data scientist (J.C.) through random sampling from the dataset. Each image was separately presented to GPT-4o without any preprocessing or modification alongside 2 prompts designed to evaluate the diagnostic capabilities of GPT-4o. Both prompts included the same list of 7 dermatologic conditions for answer choices but differed in contextual information, where prompt 1 provided patient demographic information and localization of the dermatological condition but prompt 2 did not provide these details (Table). No follow-up questions were presented.
For prompt 1, the confusion matrix showed a strong bias toward detecting mel and bcc, with high true positives (mel, 83%; bcc, 37%)(eFigure 1). This pattern possibly suggests a tendency to favor malignant labels (eg, mel, BCC) when uncertainty is present. Interestingly, df and vsl also had notable true positives (46% and 37%, respectively), which is unexpected for less critical conditions because the model’s correct classifications were uneven across benign lesions. Actinic keratoses and nv showed higher misclassification rates, suggesting the model struggled to distinguish them from other lesions.
As shown in eTable 1, prompt 1 exhibited the highest recall for mel at 0.83 but performed worse in precision (0.242) and specificity (0.567) compared to ak, which had an extremely low recall (0.03) but very high specificity (0.992) and moderate precision score (0.375). The highest precision score was seen with vsl (0.738), which also achieved high scores in specificity (0.982) and accuracy (0.88) and performed moderately well in recall (0.31). All performance metrics are reported as proportions (0-1.0), wherein 1.0 indicates 100.
For prompt 2, the second confusion matrix followed similar trends as prompt 1 but still differed in key areas (eFigure 2). Melanoma detection remained strong (true positives, 95%), while bcc shows slightly fewer true positives (24%). Vascular skin lesions improve in true positives (40%), and df dropped slightly (33%). The model continues to struggle with ak and nv, with notable misclassifications observed across other categories
Similar to prompt 1, prompt 2 achieved its highest recall for mel (0.95%), but demonstrated lower precision (0.223%) and specificity (0.488%) for this class. Prompt 2 also produced the highest accuracy for vascular skin lesions (0.90%). The highest specificity was observed for both bk and ak (0.992% each); however, ak again demonstrated the lowest recall, with a value of 0.01%.
A previous study utilizing a model of binary classification to distinguish between mel and benign dermatologic conditions demonstrated poor performance.1 Additionally, prior studies have employed a less-strict, open-ended style question approach to examine ChatGPT’s ability to diagnose mel with limited efficacy.7 The HAM10000 dataset was specifically selected despite its limitations (including the absence of clinical images and limited diversity in skin tones) due to its comprehensive nature, robust annotation standards, and widespread acceptance in dermatologic AI research. Compared to the Diverse Dermatology Images dataset, which notably lacks skin tone diversity, HAM10000 provides a balanced representation of several dermatologic conditions crucial for multiclass classification tasks, making it suitable for benchmarking AI performance. This study aimed to eliminate these limitations by employing a multiclass classification approach; however, despite this switch, our results indicate continued and major limitations of the diagnostic capabilities of GPT-4o.
In its current form, GPT-4o appeared to demonstrate a clear accuracy bias toward correctly identifying specific and severe dermatologic conditions (eg, mel, bcc) but showed low and variable class-level performance for other categories (eg, ak, nv, df, vsl), with frequent misclassification into melanoma or basal cell carcinoma and low recall for some classes (eTables 1 and 2). This finding emphasized that GPT-4o currently lacks the reliability needed for real-life clinical applications in dermatology, as both binary and multiclass models fail to achieve consistent accurate performance across all skin conditions. Notably, GPT-4o may generate false-positive malignant classifications among patients due to its skew in predicted labels toward labeling benign lesions as malignant.
From the patient perspective, younger individuals may upload images of benign nevi only to unnecessarily fear a mel diagnosis after receiving GPT-4o results. Statistically, younger patients are less likely than older patients to have malignant lesions and more likely to instead present with common vsl or df—lesions that GPT-4o appears likely to identify correctly.8 For older users, however, the situation may differ. Beyond ak being misclassified as bcc, older patients also may encounter GPT-4o outputs that mislabel lesions as mel, raising concerns and heightening anxiety. Given the technology’s tendency to overestimate the risk of serious dermatologic conditions, this behavior poses a considerable challenge in its current state and may inadvertently intensify public anxiety around mel.
A notable limitation of our study was that, compared to publicly available datasets, the HAM10000 dataset includes only dermatoscopic images rather than a combination of clinical and dermatoscopic images. Furthermore, the HAM10000 dataset comprises images primarily from White patients, whereas other diverse databases (eg, the Diverse Dermatology Images dataset) may be more suitable for training AI algorithms to accurately diagnose skin lesions in individuals with a variety of skin tones.9
Ultimately, our results signal that major advancements in the design and training of LLMs such as GPT-4o are necessary before these systems can be integrated into dermatologic diagnostic decision-making to offer benefit rather than cause harm. Consulting a health care professional rather than relying solely on AI, which might otherwise lead to avoidable stress, unnecessary alarm, and potentially increased health care costs due to unwarranted follow-up and testing, should remain the recommended standard of care for patients suspecting a skin lesion.
- Caruccio L, Cirillo S, Polese G, et al. Can ChatGPT provide intelligent diagnoses? A comparative study between predictive models and ChatGPT to define a new medical diagnostic bot. Expert Syst Appl. 2024;235:121186. doi:10.1016/j.eswa.2023.121186
- Ferreira AL, Chu B, Grant-Kels JM, et al. Evaluation of ChatGPT dermatology responses to common patient queries. JMIR Dermatol. 2023;6:E49280. doi:10.2196/49280
- Chen R, Zhang Y, Choi S, et al. The chatbots are coming: risks and benefits of consumer-facing artificial intelligence in clinical dermatology. J Am Acad Dermatol. 2023;89:872-874. doi:10.1016/j.jaad.2023.05.088
- Chau C, Feng H, Cobos G, et al. The comparative sufficiency of ChatGPT, Google Bard, and Bing AI in answering diagnosis, treatment, and prognosis questions about common dermatological diagnoses. JMIR Dermatol. 2025;8:E60827. doi:10.2196/60827
- Zhou J, He X, Sun L, et al. Pre-trained multimodal large language model enhances dermatological diagnosis using SkinGPT-4. Nat Commun. 2024;15:5649. doi:10.1038/s41467-024-50043-3
- Tschandl P, Rosendahl C, Kittler H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci Data. 2018;5:180161. doi:10.1038/sdata.2018.161
- Shifai N, van Doorn R, Malvehy J, et al. Can ChatGPT vision diagnose melanoma? An exploratory diagnostic accuracy study. J Am Acad Dermatol. 2024;90:1057-1059. doi:10.1016/j.jaad.2023.12.062
- Cortez JL, Vasquez J, Wei ML. The impact of demographics, socioeconomics, and health care access on melanoma outcomes. J Am Acad Dermatol. 2021;84:1677-1683. doi:10.1016/j.jaad.2020.07.125
- Daneshjou R, Vodrahalli K, Novoa RA, et al. Disparities in dermatology AI performance on a diverse, curated clinical image set. Sci Adv. 2022;8:Eabq6147. doi:10.1126/sciadv.abq6147
- Caruccio L, Cirillo S, Polese G, et al. Can ChatGPT provide intelligent diagnoses? A comparative study between predictive models and ChatGPT to define a new medical diagnostic bot. Expert Syst Appl. 2024;235:121186. doi:10.1016/j.eswa.2023.121186
- Ferreira AL, Chu B, Grant-Kels JM, et al. Evaluation of ChatGPT dermatology responses to common patient queries. JMIR Dermatol. 2023;6:E49280. doi:10.2196/49280
- Chen R, Zhang Y, Choi S, et al. The chatbots are coming: risks and benefits of consumer-facing artificial intelligence in clinical dermatology. J Am Acad Dermatol. 2023;89:872-874. doi:10.1016/j.jaad.2023.05.088
- Chau C, Feng H, Cobos G, et al. The comparative sufficiency of ChatGPT, Google Bard, and Bing AI in answering diagnosis, treatment, and prognosis questions about common dermatological diagnoses. JMIR Dermatol. 2025;8:E60827. doi:10.2196/60827
- Zhou J, He X, Sun L, et al. Pre-trained multimodal large language model enhances dermatological diagnosis using SkinGPT-4. Nat Commun. 2024;15:5649. doi:10.1038/s41467-024-50043-3
- Tschandl P, Rosendahl C, Kittler H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci Data. 2018;5:180161. doi:10.1038/sdata.2018.161
- Shifai N, van Doorn R, Malvehy J, et al. Can ChatGPT vision diagnose melanoma? An exploratory diagnostic accuracy study. J Am Acad Dermatol. 2024;90:1057-1059. doi:10.1016/j.jaad.2023.12.062
- Cortez JL, Vasquez J, Wei ML. The impact of demographics, socioeconomics, and health care access on melanoma outcomes. J Am Acad Dermatol. 2021;84:1677-1683. doi:10.1016/j.jaad.2020.07.125
- Daneshjou R, Vodrahalli K, Novoa RA, et al. Disparities in dermatology AI performance on a diverse, curated clinical image set. Sci Adv. 2022;8:Eabq6147. doi:10.1126/sciadv.abq6147
Evaluating GPT-4o for Automated Classification of Skin Lesions Using the HAM10000 Dataset
Evaluating GPT-4o for Automated Classification of Skin Lesions Using the HAM10000 Dataset
Practice Points
- Even with a multiclass classification framework designed to assist GPT-4o, the model encountered notable challenges in accurately diagnosing skin lesions.
- In its current form, GPT-4o may provide inaccurate and misleading information to patients who use its interface to evaluate suspected skin lesions. Patients should continue to seek clinical consultation from health care professionals.
